
Introduction
If you have ever been curious about Sentiment Analysis or how a natural language processing (NLP) model can help you determine if a particular block of text has a positive, negative or neutral sentiment this guide will to get you started. Before we processing lets talk about how you would go about running the following code examples. Google Collaborator provides notebooks that execute code on Google’s cloud service. Which I highly recommend for beginners. If you if have a Google account you can find it in your Drive. Otherwise, you can use a Conda environment and pip install modules on your local machine. In addition, I will be using seaborn for visualization.
pip install nltk
pip install textblob
pip install flairThe aim of the following article is to teach the reader three common methods to get you started with sentiment analysis. I will provide some code which you will be able to run in Colab or Conda environment. In addition, I will discuss how to interpret the sentiment metrics and do some visualization. This article is intended for those who are just beginning their journey into this fascinating topic and is in no way a deep dive. Finally, given that sentiment analysis is commonly used on tweet I’ve chosen a tweet that I particularly enjoy.
NLTK
A popular way to begin extracting sentiment scores from text is NLTK Vader. Vader is a lexicon and rule based sentiment analysis tool specifically calibrated to sentiments most commonly expressed on social media platforms. When calculating a polarity score Vader outputs four metrics: compound, negative, neutral and positive. The compound score calculates the sum of all lexicon ratings which is normalized between -1 (most negative) and +1 (most positive). Positive, negative, and neutral represent the proportion of the text that fall into these categories.
# import libraries
import pandas as pd
import seaborn as sns
import nltk
from nltk.sentiment.vader import SentimentIntensityAnalyzer
# import model
nltk.download('vader_lexicon')
# configure size of heatmap
sns.set(rc={'figure.figsize':(35,3)})
# function to visualize
def visualize_sentiments(data):
sns.heatmap(pd.DataFrame(data).set_index("Sentence").T,center=0, annot=True, cmap = "PiYG")
# text
sentence = "To inspire and guide entrepreneurs is where I get my joy of contribution"
# sentiment analysis
sid = SentimentIntensityAnalyzer()
# call method
print(sid.polarity_scores(sentence))
# heatmap
visualize_sentiments({
"Sentence":["SENTENCE"] + sentence.split(),
"Sentiment":[sid.polarity_scores(sentence)["compound"]] + [sid.polarity_scores(word)["compound"] for word in sentence.split()]
})OUTPUT:
{‘neg’: 0.0, ‘neu’: 0.571, ‘pos’: 0.429, ‘compound’: 0.8176}
TextBlob
Another technique which provides text-processing operations in a straight forward fashion is called TextBlob. The follow method differs from Vader by returning a namedtuple with a polarity and subjectivity score. The subjectivity score will falls between [0.0, 1.0]. A score of 0.0 indicates that the text is very object and a score of 1.0 indicates that the text is very subjective. The polarity score, between [-1.0, 1.0], indicates a negative comment when the score falls bellow zero and a positive sentiment when the score is above zero.
# import libraries
import pandas as pd
import seaborn as sns
from textblob import TextBlob
# configure size of heatmap
sns.set(rc={'figure.figsize':(35,3)})
# function to visualize
def visualise_sentiments(data):
sns.heatmap(pd.DataFrame(data).set_index("Sentence").T,center=0, annot=True, cmap = "PiYG")
# text
sentence = "To inspire and guide entrepreneurs is where I get my joy of contribution"
# model
TextBlob(sentence).sentiment
# visualization
visualise_sentiments({
"Sentence":["SENTENCE"] + sentence.split(),
"Sentiment":[TextBlob(sentence).polarity] + [TextBlob(word).polarity for word in sentence.split()],
"Subjectivity":[TextBlob(sentence).subjectivity] + [TextBlob(word).subjectivity for word in sentence.split()],
})OUTPUT:
Sentiment(polarity=0.8, subjectivity=0.2)
Flair
Finally, Flair allows you to apply state-of-the-art natural language processing (NLP) models to sections of text. It works quite differently to the previously mentioned models. Flair utilizes a pre-trained model to detect positive or negative comments and print a number in brackets behind the label which is a prediction confidence.
# import libraries
import pandas as pd
import seaborn as sns
import flair
# configure size of heatmap
sns.set(rc={'figure.figsize':(35,3)})
# function to visualize
def visualise_sentiments(data):
sns.heatmap(pd.DataFrame(data).set_index("Sentence").T,center=0, annot=True, cmap = "PiYG")
# model
flair_sentiment = flair.models.TextClassifier.load('en-sentiment')
# text
sentence = "To inspire and guide entrepreneurs is where I get my joy of contribution"
# sentiment
s = flair.data.Sentence(sentence)
flair_sentiment.predict(s)
total_sentiment = s.labels
total_sentiment
# tokenize sentiments
tokens = [token.text for token in s.tokens]
ss = [flair.data.Sentence(s) for s in tokens]
[flair_sentiment.predict(s) for s in ss]
sentiments = [s.labels[0].score * (-1,1)[str(s.labels[0]).split()[0].startswith("POS")] for s in ss]
# heatmap
visualise_sentiments({
"Sentence":["SENTENCE"] + tokens,
"Sentiment":[total_sentiment[0].score *(-1,1)[str(total_sentiment[0]).split()[0].startswith("POS")]] + sentiments,
})OUTPUT:
[NEGATIVE (0.9654256105422974)]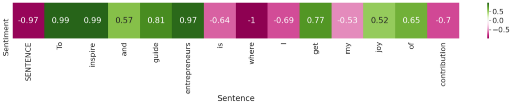
Conclusion
Using natural language processing models to perform sentiment analysis on a particular text can be a powerful tool for Data Science. For example, adding features to a pandas DataFrame using these sentiment analysis tools which is intended for a Machine Learning model to predict if the text is safe to post in a comment section or not can be a good project for starters. I would encourage readers to try and run the code for yourself and will include my Colab notebook.
Reference
- Hutto, C.J. & Gilbert, E.E. (2014). VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text. Eighth International Conference on Weblogs and Social Media (ICWSM-14). Ann Arbor, MI, June 2014.
- TextBlob, 2017, https://textblob.readthedocs.io/en/dev/
- Akbik, Alan, et al. “FLAIR: An Easy-to-Use Framework for State-of-the-Art NLP.” Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations). 2019.