![]()
Introduction
In recent years, many articles have highlighted the toxic world of internet comments and intenet posts. Reddit has announced its "anti-evil team" and YouTube has diasbled the comments section on videos featuring children. The internet of today is a far cry from the early days when cyber-utopians heralded in a new era of human collaboration and communication. While furfilling my role as a Data Science Intern at Big Armor, our team was tasked to come up with an application to be used by social workers to monitor and report potentially harmful and toxic online behavior. Systems exist to detect toxicity, suicidality, and other concerning behavior, but they are all either whole system programs or limited to a small number of topics. The model that performs best is a Bi-directional LSTM + GRU neural network made with PyTorch.
Models and Metrics
Our model is used to determine if text contains the following characteristics:
- toxic
- severe toxic
- obscene
- threat
- insult
- identity hate
The API returns clean text, labeled True or False, and the predicted probability of each. The current model is a Bi-directional LSTM + GRU neural network made with PyTorch, assuming FastText vectorization. Considerable preprocessing is performed on the text before vectorization. The metrics used for evaluation are F1 and ROC-AUC scores.
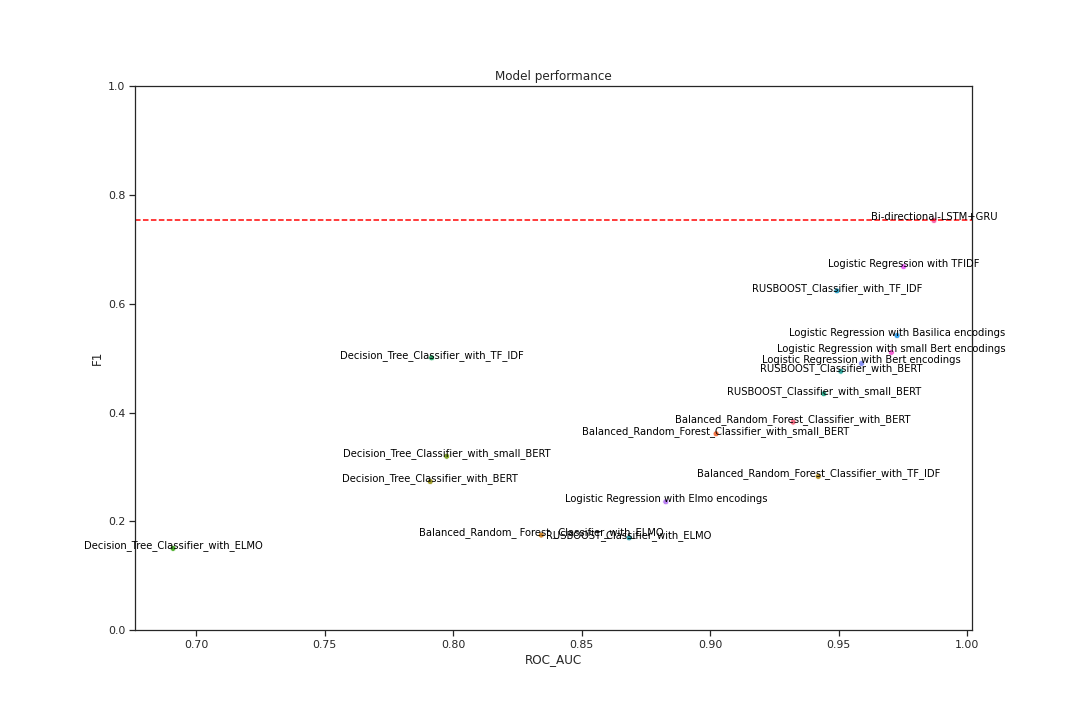
F1 score is defined as the harmonic mean between precision and recall and is measured on a scale from 0 to 1. Recall demonstrates how effectively this model identifies all relevant instances of toxicity. Precision demonstrates how effectively the model returns only these relevant instances. The AUC score represents the measure of separability, in this case, distinguishing between toxic and non-toxic content. Also on a scale of 0 to 1, a high AUC score indicates the model successfully classifies toxic vs non-toxic. The ROC represents the probability curve. The F1 score for this model is 0.753 and the ROC-AUC score is 0.987. The figure above shows all the various models our team assembled with top performing model show on the top right hand side of the chart.